Ron est un ingénieur à la retraite et directeur d’IBM et d’autres entreprises de haute technologie. Il écrit abondamment et en profondeur sur la technologie moderne.

Découvrez-en plus sur l’apprentissage fédéré, qui nous permet de former efficacement l’IA tout en minimisant les problèmes de confidentialité.
Mike MacKenzie (CC BY 2.0)
L’utilisation de l’intelligence artificielle (IA) et de l’apprentissage automatique (ML) pour extraire de la valeur de montagnes de données s’accélère. Dans des domaines tels que le marketing, la santé, les véhicules autonomes, la banque et l’Internet des objets (IoT), la capacité de l’IA/ML* à discerner des modèles et des corrélations subtils dans de grands ensembles de données fournit des informations et des capacités qui n’étaient pas disponibles auparavant.
Pour accomplir sa magie, un modèle ou un algorithme d’apprentissage automatique doit être « formé » pour discerner les modèles d’intérêt dans les données qu’il ingère. La précision du modèle dépend directement de la quantité de données utilisées pour l’entraîner. C’est pourquoi, dans la plupart des cas d’utilisation réels, la production d’un modèle d’IA/ML efficace et utile nécessite d’énormes quantités de données d’apprentissage. Et cela pose un problème de respect de la vie privée.
* Aux fins de cet article, nous utiliserons indifféremment les termes IA, ML et IA/ML.
La confidentialité est un problème majeur pour l’IA aujourd’hui
Voici un exemple du problème.
Le développement d’algorithmes d’IA/ML qui peuvent aider de manière fiable les médecins à diagnostiquer des conditions médicales nécessite que les modèles soient formés à l’aide d’immenses quantités de données provenant de vrais patients. La quantité et la variété des données requises vont bien au-delà de ce qu’un seul hôpital pourrait fournir. Traditionnellement, cela signifiait que les données de nombreuses institutions devaient être regroupées dans un référentiel centralisé pour agréger l’énorme quantité nécessaire à la formation du modèle ML.
Mais avec l’accent mis aujourd’hui sur la confidentialité, le partage des informations personnelles des patients est devenu extrêmement problématique. Le règlement général sur la protection des données (RGPD) de l’Union européenne, par exemple, interdit strictement l’échange d’informations personnelles (PI) d’un individu entre différentes organisations sans l’autorisation expresse de cette personne. Elle permet également aux individus de contrôler l’utilisation qui peut être faite de leurs informations. L’impossibilité d’obtenir le consentement de chaque personne dont les données font partie d’un ensemble de données de formation limite considérablement le développement d’assistants de diagnostic IA/ML efficaces.
Mais une nouvelle approche initialement développée par Google en 2017, appelée Federated Learning, permet de former des modèles d’IA sans l’obligation de partager et de consolider des informations privées.
Qu’est-ce que l’apprentissage fédéré ?
L’apprentissage fédéré a été développé comme un moyen d’éliminer l’exigence d’un magasin central de données brutes pour la formation des modèles d’IA. Au lieu de cela, la formation du modèle est effectuée à chaque source de données. (Les exemples de sources de données, souvent appelées terminaux ou clients, incluent les smartphones des consommateurs, les appareils IoT, les véhicules autonomes et les systèmes électroniques d’information sur la santé.) Seules les mises à jour de modèles, et jamais les données brutes résidant sur les terminaux, sont envoyées à un emplacement central
Voici comment ça fonctionne.
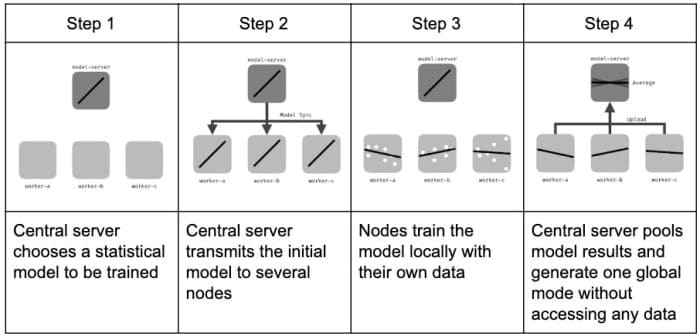
Ce diagramme montre comment fonctionne l’apprentissage fédéré.
Jérômemétronome via Wikimedia (CC BY-SA 4.0)
Le processus d’apprentissage
Tout d’abord, un modèle générique d’apprentissage automatique est généré sur un serveur central. Ce modèle, qui n’est rien de plus qu’une ligne de base de départ, est distribué à tous les terminaux ou appareils clients. Dans le cas des smartphones ou des appareils IoT, par exemple, ceux-ci pourraient se chiffrer en millions. C’est chez les clients que résident les données brutes, y compris toute information personnelle potentiellement sensible ou protégée.
Chaque client met à jour le modèle ML qu’il reçoit du serveur central, en utilisant ses propres données comme entrées de formation. Le client renvoie ensuite son modèle mis à jour localement au serveur central, qui agrège les mises à jour de tous les clients et les utilise pour générer un nouveau modèle de référence. La nouvelle ligne de base est ensuite distribuée aux clients et le cycle est répété jusqu’à ce que la ligne de base soit optimisée.
Pourquoi ce processus est précieux
Dans son annonce de cette nouvelle technologie, Google a fourni un exemple concret et réel de sa valeur. Bien que la plupart des utilisateurs ne le sachent pas, chaque fois qu’ils saisissent du texte dans leur smartphone, ils utilisent l’IA. En effet, les smartphones utilisent un modèle de texte prédictif basé sur l’IA pour tenter de prédire le mot suivant lorsque vous commencez à taper du texte dans le téléphone.
Comme Karen Hao, journaliste en intelligence artificielle pour le Examen de la technologie MITnote dans un article récent, c’est l’apprentissage fédéré qui « a permis à Google d’entraîner son modèle de texte prédictif sur tous les messages envoyés et reçus par les utilisateurs d’Android, sans jamais les lire ni les supprimer de leurs téléphones ».
Faites défiler pour continuer
Impact sur l’apprentissage automatique
L’apprentissage fédéré devrait changer fondamentalement la façon dont les modèles d’IA sont développés. Un bon exemple de cette transformation est la façon dont les modèles d’IA médicale sont formés. Avant l’avènement de l’apprentissage fédéré, la nécessité d’accumuler d’énormes quantités de données à un emplacement central limitait considérablement la capacité des chercheurs à développer des modèles de diagnostic d’IA efficaces. Comme le dit Karen Hao,
« Vous ne pouvez pas déployer un modèle de détection du cancer du sein dans le monde alors qu’il n’a été formé que sur quelques milliers de patientes du même hôpital. Tout cela pourrait changer avec l’apprentissage fédéré.
Aujourd’hui, la plupart des organisations ne disposent que d’un nombre limité de données générées en interne qu’elles peuvent utiliser pour former leurs modèles d’IA ; et ils font face à d’énormes obstacles, en raison de restrictions légales, réglementaires ou commerciales, pour acquérir des données de formation valides auprès d’autres organisations afin d’augmenter les données disponibles en interne. L’apprentissage fédéré devrait donner un formidable élan à l’utilisation de l’IA dans des domaines tels que la médecine, l’IdO, les véhicules autonomes, etc., en permettant aux organisations de collaborer à la création de modèles d’IA précis tout en conservant leurs données personnelles ou professionnelles sensibles en toute sécurité en interne.
Problèmes potentiels
La formation de modèles d’IA est un processus gourmand en calcul et en mémoire. Étant donné que l’apprentissage fédéré nécessite qu’une telle formation ait lieu sur des appareils terminaux tels que des smartphones, des véhicules autonomes ou des appareils IoT, la charge de calcul sur ces appareils pourrait perturber leurs fonctions normales. Une approche pour atténuer ces difficultés consiste à planifier les processus de formation du modèle d’IA à des moments où l’appareil serait normalement inactif.
De plus, le fait que des millions d’appareils envoient et reçoivent des mises à jour de modèles sur un réseau peut entraîner des problèmes de limitation de la bande passante. Google a résolu ce problème avec son algorithme de moyenne fédérée, qui peut former des réseaux profonds en utilisant 10 à 100 fois moins de communication par rapport à une implémentation dépourvue de cette fonctionnalité.
Un autre problème, peut-être plus grave, est la vulnérabilité de l’apprentissage fédéré à ce qu’on appelle «l’empoisonnement des modèles». Étant donné qu’un modèle d’IA d’apprentissage fédéré est développé en ingérant des données de mise à jour de modèle à partir d’un grand nombre d’appareils d’extrémité, les acteurs malveillants peuvent avoir la possibilité de compromettre le modèle final en fabriquant ou en « empoisonnant » les informations de mise à jour du modèle envoyées par certains appareils d’extrémité. Cela pourrait leur permettre de créer des portes dérobées dans le modèle.
Étant donné que les données de mise à jour du modèle sont extrêmement difficiles à interpréter pour les humains et que le maintien de l’anonymat de la source d’informations du modèle est une caractéristique de conception de nombreuses implémentations d’apprentissage fédéré, l’identification de la source, voire de l’existence, d’informations entachées fournies au modèle de base pourrait être extrêmement difficile. Se protéger contre cette possibilité impliquera probablement le développement d’une sorte de stratégie « définir un bon modèle d’IA pour détecter un mauvais modèle d’IA ».
L’avenir de l’apprentissage fédéré
La possibilité de former des modèles d’IA/ML sans violer la confidentialité des données est une énorme avancée technologique. C’est pourquoi l’apprentissage fédéré a le potentiel de changer la donne dans de nombreux domaines d’application de l’IA, notamment la vision par ordinateur, le traitement du langage naturel, les soins de santé, les véhicules autonomes, l’IoT et les applications de prédiction et de recommandation à grande échelle utilisées dans les systèmes de commerce électronique. . Il ne serait pas exagéré de dire que, dans une large mesure, l’apprentissage fédéré remodèle l’avenir de l’IA.
© 2020 Ronald E Franklin
Ronald E. Franklin (auteur) de Mechanicsburg, Pennsylvanie le 21 juillet 2020 :
Très apprécié, Jo.
Ronald E. Franklin (auteur) de Mechanicsburg, Pennsylvanie le 21 juillet 2020 :
Merci, Éric.
Jo Miller du Tennessee le 21 juillet 2020 :
Très complet et informatif.
Eric Dierker de Spring Valley, Californie. États-Unis le 20 juillet 2020 :
Comme c’est très intéressant et tellement pertinent aujourd’hui. Je dois admettre que je suis très facilement modelable et cela me convient.