Tesfaye écrit sur les architectures d’apprentissage en profondeur et d’autres concepts de programmation informatique.

Architecture d’apprentissage en profondeur pour la reconnaissance vocale
Photo de Kevin Ku sur Unsplash
Aperçu
Ce projet construit un modèle de reconnaissance vocale en amharique à l’aide de Keras/Tensorflow. Différents programmes d’apprentissage en profondeur ont été discutés, mais nous avons choisi l’architecture CNN-RNN, en construisant trois modèles qui incluent Simple RNN, CNN avec Simple RNN et CNN RNN bidirectionnel.
Objectif du projet
La technologie de reconnaissance vocale permet un contrôle mains libres des smartphones, des haut-parleurs et même des véhicules dans une grande variété de langues. Le Programme alimentaire mondial souhaite déployer un formulaire intelligent qui recueille des informations nutritionnelles sur les aliments achetés et vendus sur les marchés de deux pays différents d’Afrique : l’Éthiopie et le Kenya.
L’objectif du projet est de fournir une technologie de synthèse vocale pour la langue amharique. Nous avons utilisé un algorithme d’apprentissage en profondeur pour construire un modèle capable de transcrire un discours en texte.
Les outils suivants ont été utilisés dans ce projet.
MLflow
Il s’agit d’un cadre qui joue un rôle essentiel dans tout cycle de vie d’apprentissage automatique de bout en bout. Il permet de suivre vos expériences ML, y compris le suivi de vos modèles, paramètres de modèle, ensembles de données et hyperparamètres et de les reproduire si nécessaire.
Les avantages de MLflow sont :
- Il est facile de mettre en place un mécanisme de suivi des modèles.
- Il propose des API très intuitives pour le service.
- Il fournit la collecte de données, la préparation des données, la formation du modèle et la mise en production du modèle.
Contrôle de version des données, ou DVC
Il s’agit d’un outil de gestion des données et des expériences ML qui tire parti de l’ensemble d’outils d’ingénierie existant que nous connaissons (Git, CI/CD, etc.).
- Parallèlement à la gestion des versions des données, DVC permet également le suivi des modèles et des pipelines.
- Avec DVC, vous n’avez pas besoin de reconstruire les modèles précédents ou les techniques de modélisation des données pour obtenir le même état de résultats passé.
- Parallèlement à la gestion des versions des données, DVC permet également le suivi des modèles et des pipelines.
Apprentissage automatique continu (CML)
Il s’agit d’un ensemble d’outils et de pratiques qui apporte des processus CI/CD largement utilisés à un flux de travail d’apprentissage automatique.
flux tenseur
Il s’agit d’une plate-forme open source de bout en bout, une bibliothèque pour plusieurs tâches d’apprentissage automatique. Il fournit une collection de flux de travail pour développer et former des modèles à l’aide de Python ou JavaScript, et pour les déployer facilement dans le cloud, sur site, dans le navigateur ou sur l’appareil, quel que soit le langage que vous utilisez.
Keras
Il s’agit d’une API d’apprentissage en profondeur de haut niveau développée par Google pour la mise en œuvre de réseaux de neurones. Il est écrit en Python et est utilisé pour faciliter la mise en œuvre de réseaux de neurones. Il prend également en charge le calcul de plusieurs réseaux neuronaux principaux. Il fonctionne au-dessus de Tensorflow.
Rendez-vous
Pour ce projet, nous avons utilisé des données audio amhariques avec transcription, qui ont été préparées par Getalp. Ils ont préparé plus de 10 000 clips audio totalisant plus de 20 heures de discours. Chaque clip dure quelques secondes et est accompagné de sa transcription. Il existe également quelques centaines de clips séparés à des fins de test.
Préparation des dates de formation
Les données de formation pour ce projet comprennent :
Faites défiler pour continuer
- Les caractéristiques (X) sont les chemins des fichiers audio
- Les marqueurs cibles (y) sont les transcriptions

Métadonnées générées à partir des données fournies
Prétraitement des données
Chargement des données : Chargez des fichiers audio à l’aide du module labrosa Python et obtenez le tableau d’échantillons et la fréquence d’échantillonnage des audios.
Normaliser le taux d’échantillonnage : Le taux d’échantillonnage audio par défaut pour chaque audio était de 16 kHz.
Redimensionnement audio : Tous les fichiers audio devaient avoir la même longueur afin d’obtenir un meilleur résultat avec la modélisation. Ils ont donc redimensionné à près de quatre secondes.
Convertir en chaînes : Tous les fichiers audio ont été convertis en canaux stéréo car chaque fichier audio doit avoir des canaux similaires.
Augmentation des données : Pour augmenter la quantité de données en ajoutant des données légèrement modifiées à partir de données existantes. Il agit comme un régularisateur et aide à réduire le surajustement lors de la formation d’un modèle d’apprentissage automatique. J’ai montré différentes techniques d’augmentation avec les résultats ci-dessous.
Extraction de caractéristiques: Dans cette étape de prétraitement, nous avons créé des métadonnées qui incluent des fonctionnalités audio à utiliser ultérieurement dans le pipeline de prétraitement. Les colonnes de métadonnées incluent le chemin d’accès au fichier, la durée de l’audio, le texte (traduction) et le canal.
Augmentation des données sur un échantillon audio sélectionné
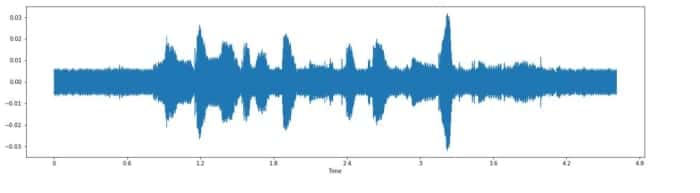
Échantillon audio original
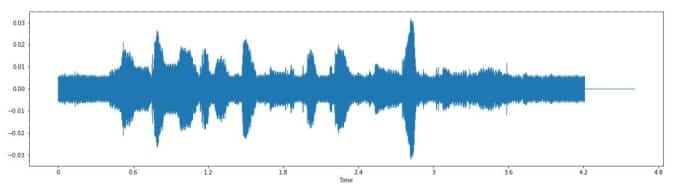
Décalage horaire par facteur 5
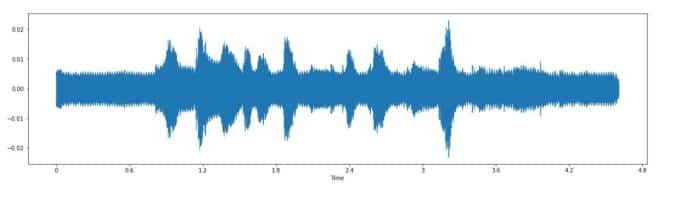
changer de frequence
Architectures d’apprentissage en profondeur
Il existe de nombreuses variantes d’architecture d’apprentissage en profondeur pour l’ASR. Deux approches couramment utilisées sont :
- Une architecture CNN (Convolutional Neural Network) plus basée sur RNN (Recurrent Neural Network) qui utilise l’algorithme CTC Loss pour délimiter chaque caractère des mots dans le discours. par exemple. Modèle Deep Speech de Baidu.
- Un réseau séquence à séquence basé sur RNN qui traite chaque « tranche » du spectrogramme comme un élément dans une séquence. Modèle Listen Attend Spell (LAS) de Google.
Pour ce projet, nous avons choisi d’utiliser l’architecture basée sur CNN-RNN.
Modèles d’apprentissage en profondeur et résultats
Modèle RNN simple : Les réseaux de neurones récurrents sont l’architecture d’apprentissage en profondeur la plus préférée et la plus utilisée en raison de leur capacité à modéliser des données séquentielles, y compris la reconnaissance vocale. Le premier modèle que j’ai essayé avait une couche RNN avec Gated Recurrent Unit (GRU), un type simplifié de neurone récurrent à mémoire à long terme avec moins de paramètres que le LSTM typique. Enfin, il existe une couche softmax pour générer les probabilités de lettre.
CNN avec RNN : Les réseaux de neurones convolutifs (CNN) sont un type d’architecture d’apprentissage en profondeur qui est spécialisé pour être principalement utilisé dans l’analyse d’ensembles de données visuelles. Ils utiliseront le spectrogramme des signaux vocaux représentés sous forme d’image et reconnaîtront la parole en fonction de ces caractéristiques. Nous avons utilisé deux combinaisons de CNN (couche unidimensionnelle) et RNN (RNN simple et utilisant une couche LSTM bidirectionnelle).
Reconnaissance vocale utilisant un algorithme RNN simple

Reconnaissance vocale utilisant un algorithme RNN simple

Reconnaissance vocale utilisant CNN avec RNN simple



Reconnaissance vocale utilisant CNN avec RNN bidirectionnel



Conclusion et travaux futurs
Tout au long du projet, de nombreux algorithmes d’apprentissage en profondeur ont été discutés et, comme nous pouvons le voir sur le résultat, plus nous affinons les paramètres des algorithmes que nous avons utilisés, meilleurs sont les résultats.
La reconnaissance vocale de la langue amharique n’est pas comme de nombreux systèmes de reconnaissance vocale matures disponibles, et a encore besoin de plus de données de formation car d’autres ont plus de 100 000 heures de données par rapport aux données que nous avons utilisées (20 heures).
L’utilisation de la modélisation du langage améliorera également la prédiction des phrases en amharique, ce qui peut en fait aider à une meilleure reconnaissance de la parole.
Lien GitHub vers le projet
- Discours amharique au texte
Reconnaissance vocale en langue africaine – Speech-to-Text – GitHub – tesfayealex/Speech-to-Text: Reconnaissance vocale en langue africaine – Speech-to-Text
Ce contenu est exact et fidèle au meilleur de la connaissance de l’auteur et ne vise pas à remplacer les conseils formels et individualisés d’un professionnel qualifié.