Tesfaye écrit sur des projets impliquant une architecture d’apprentissage en profondeur et des technologies décentralisées comme la blockchain et les NFT.
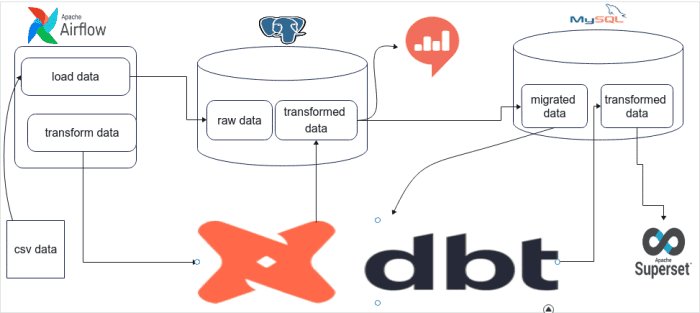
Flux de travail du projet de migration de données
Aperçu du projet
Auparavant, nous avons construit un entrepôt de données ELT en utilisant les données de trafic. Au fur et à mesure que le projet continue d’utiliser la base de données PostgreSQL et Redash, nous allons également migrer les données de mon entrepôt de données PostgreSQL vers l’entrepôt de données MySQL et automatiser l’ensemble de la tâche. De plus, je changerai l’outil de visualisation du tableau de bord du sous-ensemble Redash au sous-ensemble Apache.
Objectif du projet
L’objectif de ce projet réside dans la compréhension et l’application des changements et de l’automatisation en ce qui concerne le pipeline ELT et l’entrepôt de données. Dans le projet précédent, nous avons construit un entrepôt de données en utilisant PostgreSQL, Airflow, DBT et Redash.
Cette fois-ci, nous visons à créer et à gérer le processus d’automatisation de l’entrepôt de données à mesure que les données migrent vers Mysql, Airflow, DBT et le sur-ensemble Apache. Ce projet serait utile aux ingénieurs de données ou à toute personne effectuant des processus de migration, de modification et d’automatisation des données.
- Flux d’air Apache — Un gestionnaire de flux de travail pour planifier, orchestrer et surveiller les flux de travail. Les graphiques acycliques dirigés (DAG) sont utilisés par Airflow pour contrôler l’orchestration du flux de travail.
- PostgresqlName — Un système de gestion de base de données relationnelle objet (ORDBMS) mettant l’accent sur l’extensibilité et la conformité aux normes. Il s’agit de la base de données à partir de laquelle nous allons migrer les données.
- DBT (outil de création de données) — Permet de transformer les données dans les entrepôts en écrivant simplement des instructions de sélection. Il gère la transformation de ces instructions de sélection en tables et en vues.
- Redash — Une application Web open-source utilisée pour effacer les bases de données et visualiser les résultats. Il s’agit de l’outil de création de tableau de bord à partir duquel nous allons migrer.
- Sur-ensemble Apache — Une plateforme open-source de visualisation et d’exploration de données. Il est rapide, léger, intuitif et doté d’options qui permettent aux utilisateurs de toutes compétences d’explorer et de visualiser facilement leurs données, des simples graphiques linéaires aux graphiques géospatiaux très détaillés.
Données utilisées
Les données que nous utiliserons pour ce projet peuvent être téléchargées à partir des données pNEUMA. pNEUMA est un ensemble de données ouvert à grande échelle des trajectoires naturalistes d’un demi-million de véhicules dans le centre-ville encombré d’Athènes, en Grèce. L’expérience unique en son genre a utilisé un essaim de drones pour collecter les données. Chaque fichier pour un seul (zone, date, heure) représente environ 87 Mo de données. Ces données ont été stockées dans la base de données PostgreSQL (voir dans mon dernier article).
Phases du projet
Dans ce projet, nous utiliserons PostgreSQL comme ancienne base de données et la migrerons vers la base de données MySQL. Ensuite, nous activerons la transformation à l’aide de DBT. Enfin, nous allons construire un tableau de bord.
- Préparer l’entrepôt de données PostgreSQL (que nous avons déjà)
- Écrire des Airflow Dags qui migreront les données de PostgreSQL vers MySQL
- Écrire des codes DBT pour activer la transformation
- Créer des tableaux de bord à l’aide d’Apache Superset
Écrire des Dags de flux d’air
À ce stade, nous avons déjà les données, donc la partie principale du projet – la migration d’une base de données vers une autre base de données – peut devenir difficile. Mais ici, je vais montrer comment j’ai pu migrer mes données de Postgres vers MySQL.
Ce code nous permettra d’obtenir tous les noms de schéma avec leur nom de table à partir d’un paramètre de nom de base de données.
Codes de l’utilitaire de migration
def convert_type(type):
if type == "boolean":
return "bit(1)"
elif type == "integer":
return "int"
elif type == "double precision":
return "double"
elif type == "character varying":
return "LONGTEXT"
elif type == "text":
return "LONGTEXT"
else:
return type
def create_table_query(table,columns):
create_query = f"USE {table[0]}; CREATE TABLE IF NOT EXISTS {table[1]}("
for index , c in enumerate(columns):
data_type = convert_type(c[2])
nullable = "NULL" if c[1] == "YES" else "NOT NULL"
if index != 0:
create_query += ','
create_query += "`" + str(c[0]) + "`" + " " + str(data_type) + " " + str(nullable)
create_query += ") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE utf8mb4_unicode_ci;"
return create_query
def create_db_query(name):
db_query = f"CREATE DATABASE IF NOT EXISTS {name}"
return db_query
def get_schema_and_table_name(database_name):
connection = db_connect.connect(host=host_name,user=db_user,password=db_password,database=database_name)
cursor = connection.cursor()
query = f'SELECT table_schema,table_name FROM information_schema.tables WHERE table_schema != "pg_catalog" and table_schema != "information_schema" ORDER BY table_schema'
cursor.execute(query)
schemas = cursor.fetchall()
return schemas
Ce code va nous permettre de créer dynamiquement notre base de données et notre table. C’est l’une des fonctions importantes car ce sont généralement les premières étapes de la migration des données. La fonction « get_schema_and_table_name » nous permettra d’obtenir tous les noms de schéma avec leur nom de table à partir d’un paramètre de nom de base de données.
Faites défiler pour continuer
Codes de l’orchestrateur de migration de données
def start_workflow(database_name):
schema = get_schema_and_table_name(database_name)
create_schemas_and_load_data(database_name , schema)
def create_schemas_and_load_data(database_name , schemas):
connection = db_connect.connect(host=host_name,user=db_user,password=db_password,database=database_name)
postgres_engine = create_engine(f'postgresql+psycopg2://{db_user}:{db_password}@{host_name}/{database_name}')
cursor = connection.cursor()
for s in schemas:
query = f"SELECT column_name , is_nullable , data_type FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA= '{str(s[0])}' and TABLE_NAME = '{str(s[1])}'"
cursor.execute(query)
columns = cursor.fetchall()
mysql_connection = f'mysql://admin:admin@127.0.0.1:3306/{database_name}'
engine = create_engine(mysql_connection)
conn = engine.connect()
db_query = create_db_query(s[0])
db = conn.execute(db_query)
singe_db_connection = f'mysql://admin:admin@127.0.0.1:3306/{s[0]}'
single_db_engine = create_engine(singe_db_connection)
single_db_conn = engine.connect()
create_query = create_table_query(s,columns)
conn.execute(create_query)
the_data = pd.read_sql(f'SELECT * FROM {s[0]}.{s[1]}',postgres_engine)
x = the_data.to_sql(s[1], con=single_db_engine, if_exists='replace', index=False)
get_data_query = f'select * from {s[0]}.{s[1]};'Ce sont probablement les codes les plus importants de notre projet car ce sont eux qui orchestrent et appellent chaque fonction. La fonction « create schemas_and_load_data » gère le processus après avoir récupéré les noms de schéma et de table depuis PostgreSQL. Son résumé de processus serait le suivant :
- Obtenir tous les noms de colonne, la capacité nulle et les types de données de toutes les tables
- Créer une requête de création de base de données MySQL
- Créer une requête de création de table MySQL (en utilisant les fonctions ci-dessus)
- Lire les données de la base de données PostgreSQL à l’aide de pandas
- Écrire des données dans la base de données MySQL à l’aide de pandas
Airflow Dags pour appeler les fonctions ci-dessus
with DAG(
dag_id='migrate_data',
default_args=default_args,
description='migrate data from postgres to mysql',
start_date=datetime(2022,7,6,2),
schedule_interval='@once'
)as dag:
task1 = PythonOperator(
task_id='create_schema_and_migrate_data',
python_callable=start_workflow,
op_kwargs={'database_name': 'Warehouse' },
)
task2 = PythonOperator(
task_id='create_dataset_table',
python_callable=migrate_privilages,
op_kwargs={'database_name': 'Warehouse' },
)
task3 = PythonOperator(
task_id='create_schema_and_migrate_data_2',
python_callable=start_workflow,
op_kwargs={'database_name': 'trial' },
)
task4 = PythonOperator(
task_id='create_dataset_table_2',
python_callable=migrate_privilages,
op_kwargs={'database_name': 'trial' },
)
task1 >> task2 >> task3 >> task4Codes de migration de privilège
def migrate_privilages(database_name):
connection = db_connect.connect(host=host_name,user=db_user,password=db_password,database=database_name)
cursor = connection.cursor()
query = f"SELECT * FROM information_schema.table_privileges"
cursor.execute(query)
columns = cursor.fetchall()
for c in columns:
if c[1] == 'try_user':
check_user_existance = f'SELECT user,host FROM mysql.user where user = "{c[1]}"'
query = f'GRANT {c[5]} on {c[3]}.{c[4]} to {c[1]}@`localhost`;'
mysql_connection = f'mysql://{db_user}:{db_password}@{host_name}:3306/{c[3]}'
engine = create_engine(mysql_connection)
conn = engine.connect()
excuted = conn.execute(check_user_existance)
if len(excuted.fetchall()) == 0:
create_user_query = f'CREATE USER {c[1]}@`{host_name}` IDENTIFIED WITH mysql_native_password BY "password";'
excuted = conn.execute(create_user_query)
if c[5] != "TRUNCATE":
excuted = conn.execute(query)
À ce stade, nous avons migré toutes les données de PostgreSQL mais il reste à migrer les privilèges des utilisateurs, car migrer uniquement les données ne suffit pas. Donc, sur cette fonction, les étapes, en résumé, seraient :
- Obtenir tous les utilisateurs de PostgreSQL
- Vérifiez si l’utilisateur existe dans la base de données MySQL, sinon créez l’utilisateur
- Apportez tous les privilèges liés à l’utilisateur
Codes DBT pour MYSQL
Les codes DBT ici ne sont pas très différents des codes PostgreSQL DBT. Voici un petit code DBT pour MySQL :
schema.yml
version: 2
models:
- name: import_data
description: "traffic data"
columns:
- name: id
description: "unique id"
- name: track_id
description: "track id"
- name: type
description: "type"
- name: traveled_d
description: "traveled_d"
- name: avg_speed
description: "avg_speed"
- name: lat
description: "lat"
- name: lon
description: "lon"
- name: speed
description: "speed"
- name: lon_acc
description: "lon_acc"
- name: lat_acc
description: "lat_acc"
- name: time
description: "time"
traffic_dbt_model.sql
{{ config(materialized='view') }}
with traffic_dbt_model as (
select * from public.import_data
)
select *
from traffic_dbt_modeltraffic_avg_speed_by_type_model.sql
select " type" , AVG(" avg_speed")
from {{ ref('traffic_dbt_model') }}
Group by " type"
Ces codes DBT créeraient plusieurs vues transformant les données. Après ce DBT nous permettrait de documenter nos modèles et de les servir localement.
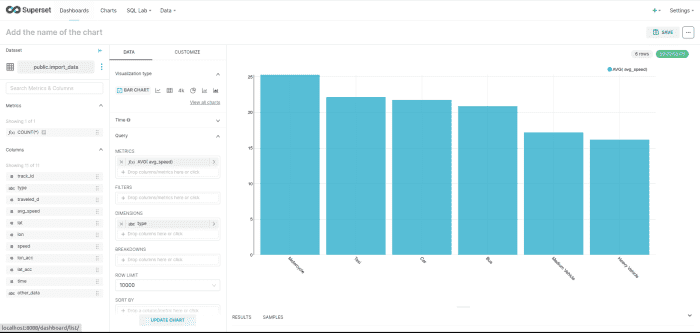
Construire un tableau de bord à l’aide d’Apache Superset
Apache Superset est vraiment un outil puissant qui permet de créer des tableaux de bord avec une interface utilisateur de visualisation et également à partir de requêtes SQL. Voici quelques-uns des graphiques que j’ai pu créer.
Défis du projet et plats à emporter
Ce projet a été utile pour comprendre le processus de migration des données et les défis auxquels nous pourrions être confrontés dans les projets de migration de données du monde réel. De plus, nous avons pu comprendre la structure des bases de données PostgreSQL et MySQL et des modèles de privilèges. Certains pointeurs incluent :
- Tout en travaillant sur ce projet, j’ai observé et recherché un module ou une application permettant de migrer des données de PostgreSQL vers MySQL. Mais tout ce que j’ai pu trouver, c’est MySQL vers Postgres, ce qui signifie que plus de personnes et d’entreprises se tournent vers Postgres et non vers MySQL. Une des raisons pourrait être l’évolutivité.
- Dans PostgreSQL, on peut stocker plusieurs schémas et chacun a la capacité de stocker plusieurs tables tandis que dans MySQL, un schéma est la base de données, ce qui signifie qu’une base de données ne peut pas avoir plusieurs schémas. Cela complique la tâche s’il existe deux bases de données avec le même schéma ou deux schémas avec les mêmes noms de table.
- La structure des privilèges utilisateur dans PostgreSQL contient plus de données que MySQL, ce qui inclut les informations sur qui a accordé quel accès à un utilisateur.
- J’ai trouvé qu’Apache Superset était facile à utiliser et avait un processus d’installation facile par rapport à Redash.
- PostgreSQL prend en charge plus de types de données que MySQL, mais MySQL a un sous-type de données qui n’est pas disponible dans PostgreSQL, ce qui rend difficile la conversion des types de données entre les bases de données.
Plans futurs et conclusion
Ce projet m’a permis d’approfondir les architectures et les modèles de bases de données dans des bases de données telles que PostgreSQL et MySQL. Cela m’a également permis de comparer des outils de création de tableaux de bord, tels que Redash et Superset. Les principaux travaux futurs comprennent :
- Analyser et permettre la migration de bases de données volumineuses (en taille) à l’aide des codes de ce projet.
- Ajout de fonctionnalités de test supplémentaires pour la migration des données.
- Créer un tableau de bord et des informations plus intuitifs.
Ce contenu est exact et fidèle au meilleur de la connaissance de l’auteur et ne vise pas à remplacer les conseils formels et individualisés d’un professionnel qualifié.