Mike Shoemake est un développeur de logiciels prospère depuis 20 ans, créant des applications de qualité et des équipes de développement hautement performantes.

Tout comme les voies et les aiguillages aident les trains à fusionner, Git est un système de contrôle de version pour la fusion de code.
La montée de Git
Git semble conquérir le monde, en ce qui concerne les systèmes de contrôle de version. Il y a dix ans, c’était Subversion qui avait retenu notre attention (la ligne rouge ci-dessous). Maintenant, Git (la ligne bleue) est fermement aux commandes.
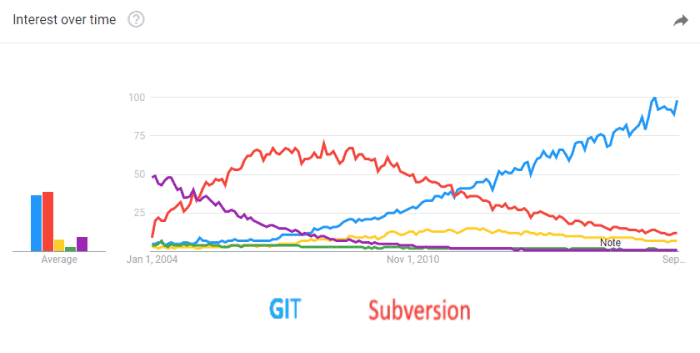
Un graphique montrant la popularité de Subversion et Git au fil du temps.
Pourtant, il y a beaucoup à apprendre avec Git. Beaucoup d’entre nous sont venus à Git après avoir passé beaucoup de temps avec Subversion ou un autre concurrent, et la façon dont nous utilisons Git reflète maintenant notre expérience et notre compréhension de ces autres outils. Nous avons appris juste assez pour survivre et nous sommes rapidement retournés à nos tâches quotidiennes.
Mais Git est très, très différent de tout autre système de contrôle de version que vous avez pu utiliser. Si vous comprenez Git, c’est votre meilleur ami. Si vous ne le faites pas, vous pouvez l’utiliser d’une manière qui crée des risques inutiles pour vous et votre équipe. Étonnamment, des problèmes de production pourraient résulter de l’utilisation de Git d’une manière pour laquelle il n’était pas censé être utilisé.
Risques inhérents aux fusions Git
Comme nous le verrons, les fusions Git ont un risque inhérent qui leur est associé au-delà des développeurs qui font un gâchis de résolution des conflits de fusion. Ce risque augmente considérablement plus nous attendons pour intégrer notre code. Il s’avère que les grandes fusions sont beaucoup plus risquées que les petites, et pourtant de nombreuses équipes de développement font de grandes fusions comme mode de vie. Votre modèle de branchement peut avoir un impact négatif sur la qualité de la production, et vous ne le savez pas encore.
Voyons d’abord comment fonctionnent les fusions Git, puis nous pourrons déterminer comment les utiliser au mieux. Dans les exemples ci-dessous, nous utiliserons SourceTree pour nous aider à visualiser ce qui se passe.
L’homme derrière le rideau : comment fonctionne Git ?
Vous pouvez penser aux fusions Git comme si vous mélangez un jeu de cartes. Git prend deux jeux de cartes distincts et les tisse ensemble en un seul jeu, lançant des extras lorsque des doublons sont trouvés.
Exemple : fusionner des commits
Considérez l’exemple ci-dessous :
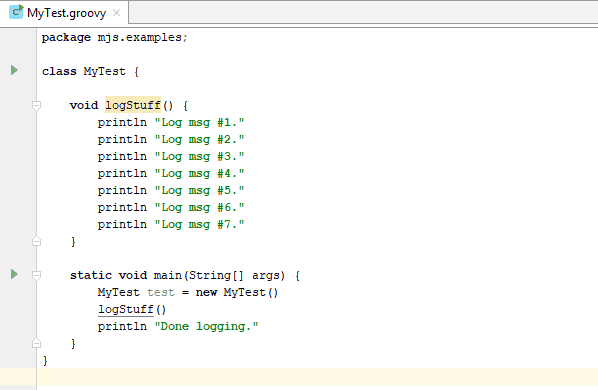
Le simple fichier de classe Groovy.
Il s’agit d’un simple fichier de classe Groovy qui ne fait que faire des appels à println(). Maintenant, deux développeurs, Jim et Fred, ont chacun modifié ce fichier en même temps, ce qui nécessitera une fusion pour être résolu.
Chacun a créé une branche, qui n’est qu’un nom auquel une série de commits peut être associée. La branche (c’est-à-dire le nom) est directement associée au commit le plus récent, donc lorsqu’un nouveau commit est fait, le nom de la branche passe au nouveau. Chaque commit pointe vers son ou ses prédécesseurs – ils ne pointent jamais vers l’avant.
Voici le compromis de Jim :
Le commit de Jim dans l’exemple.
Notez que Jim a modifié la ligne 21 pour ajouter un commentaire, et Git la considère comme un changement contigu qui inclut une suppression et un ajout.
Faites défiler pour continuer
Et voici le commit de Fred :
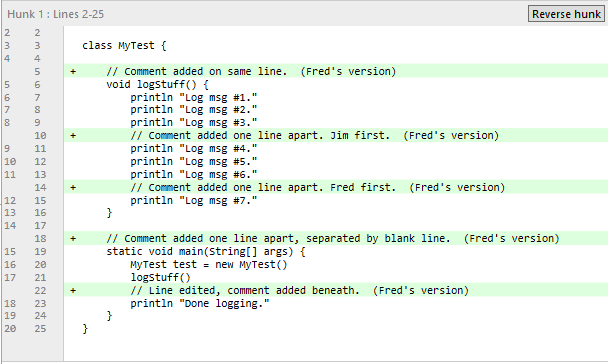
Le commit de Fred dans l’exemple.
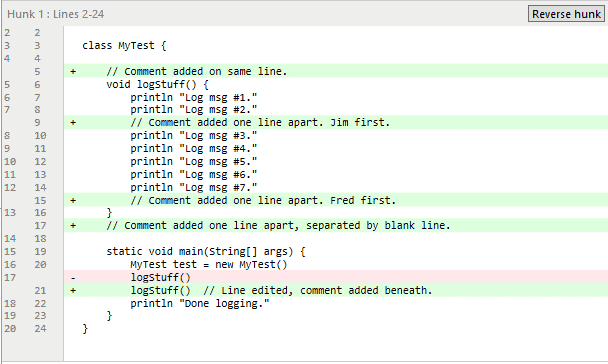
Ce qui est important, c’est qu’il y a plusieurs changements distincts ici, certains qui se chevauchent et d’autres qui ne sont séparés que d’une ligne.
Pour obtenir un aperçu de la fusion, nous pouvons mettre en surbrillance les deux commits dans SourceTree, cliquer sur le fichier source et afficher le diff résultant.

Mettre en surbrillance les deux commits.
Avec les deux commits sélectionnés, nous voyons le diff ci-dessous :
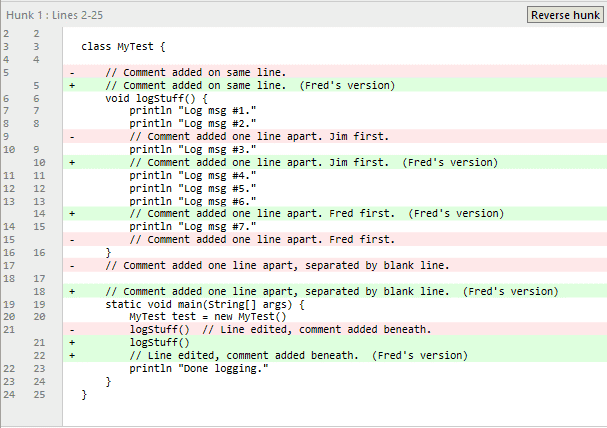
Le différentiel
Conflits de fusion
Git identifie les changements discrets, chacun étant un bloc contigu de lignes qui ont changé. Git tentera de tisser ensemble les blocs modifiés avec les blocs inchangés. Si deux blocs modifiés n’ont pas au moins une ligne inchangée entre eux, Git considère qu’il s’agit d’un conflit de fusion.
Dans cet exemple, nous pouvons déjà voir où seront les conflits de fusion :
Parce que les changements rouges et verts se « touchent » dans le diff, Git ne saura pas lequel mettre en haut. Ainsi, il signale ces modifications comme des conflits de fusion et demande au développeur de le comprendre. Étant donné que les autres modifications sont séparées par des lignes de code communes, Git doit suivre un ordre clair. Du point de vue de Git, il s’agit de savoir comment tisser les choses ensemble et s’assurer que tout est fait dans le bon ordre. Si Git n’est pas sûr, il vous demande de le résoudre vous-même.
Que se passe-t-il lors de la fusion
Voici le résultat de la fusion réelle :
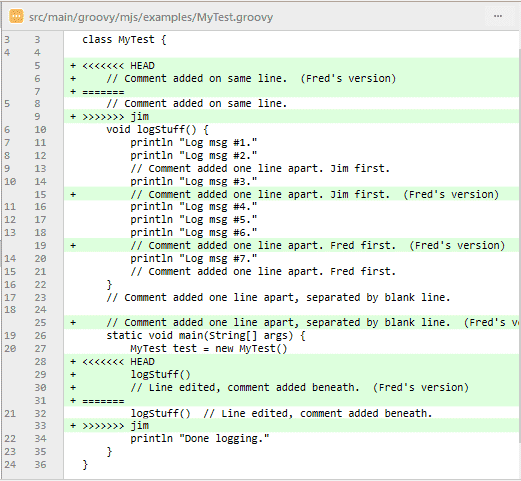
Le résultat de la fusion.
Comme vous pouvez le voir, les conflits de fusion sont apparus là où ils étaient attendus. Les lignes 29 et 30 sont considérées comme un changement contigu et sont donc incluses dans le conflit de fusion ensemble. Comme les autres changements ne se chevauchent pas, Git est capable de déterminer le bon ordre et fait le reste pour vous.
Le requin dans l’eau : Git aide-t-il ou fait-il mal ?
Git est définitivement utile en résolvant les conflits pour nous. Les développeurs adorent cette fonctionnalité ! Beaucoup d’entre nous s’appuient sur la capacité de fusion automatique de Git comme si Git était un androïde futuriste avec des compétences folles en codage qui s’occupe de notre travail léger afin que nous n’ayons pas à nous en soucier. Et pourtant, Git ne sait rien du contexte. Il n’effectue aucune analyse sémantique et n’a aucun moyen de déterminer si les modifications de deux fichiers source fusionnés vont ensemble ou s’excluent mutuellement.
Exemple 2 : Erreurs dans la fusion
Considérez l’exemple ci-dessous :
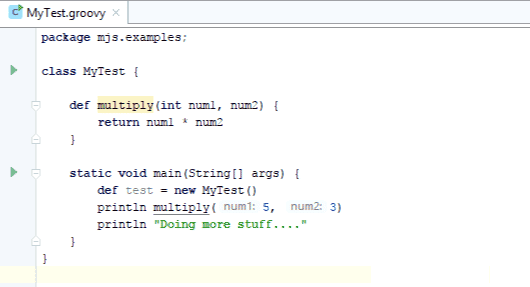
Un autre fichier source Groovy simple pour l’exemple suivant.
Il s’agit d’un fichier source Groovy très simple avec une méthode multiplier(int, int) et une méthode principale qui appelle multiplier(). C’est en fait le code qui se trouve en tête de la branche master ci-dessous.
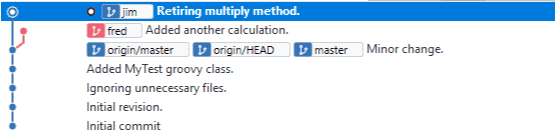
La branche maîtresse.
Fred a ajouté un nouvel appel à la méthode multiplier() :
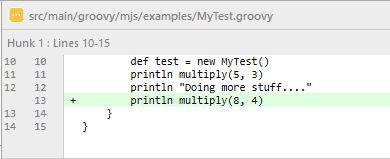
L’ajout de Fred.
À l’insu de Fred, Jim a décidé de retirer la méthode de multiplication, en la supprimant ainsi que les appels de méthode qui en dépendent.

Le résultat final de la fusion (illustré ci-dessous) inclut un appel à la méthode multiplier (), mais maintenant cette méthode n’existe plus.
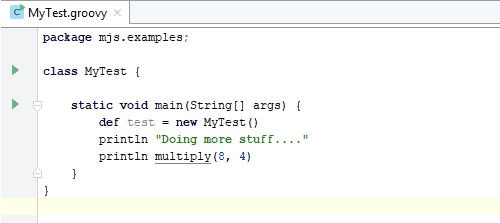
La fusion, qui appelle une méthode qui n’existe plus.
Une erreur difficile à trouver
Pire encore, ce code se compile en fait car il s’agit de Groovy et non de Java. Ainsi, la seule façon de savoir que ce problème existe est de détecter une exception au moment de l’exécution. Si votre gestion des erreurs n’est pas excellente, vous aurez peut-être du mal à suivre ce problème et vous ne réaliserez peut-être jamais qu’il a été causé par la fusion automatique de Git.
Les langages dynamiques (ex. Groovy, Javascript, Python, Ruby, et bien d’autres) sont particulièrement sensibles à ce problème en raison d’une vérification limitée au moment de la compilation. Bien qu’une solide couverture des tests unitaires/d’intégration soit certainement utile pour identifier les problèmes qui peuvent en résulter, les équipes n’ont souvent pas la couverture nécessaire pour les protéger contre les dommages.
Alors que la plupart du temps, Git fait du bon travail en résolvant les conflits pour vous, il est possible que des erreurs se produisent. Si vous associez cela à des instances de développeurs qui gèrent mal les conflits de fusion, les fusions Git comportent certainement des risques qui leur sont associés. Alors, comment atténuons-nous ce risque?
Le plat à emporter: problèmes avec les succursales
De nombreuses équipes de développement ont adopté les branches de fonctionnalités comme partie intégrante de leur modèle de création de branches. Les branches de fonctionnalités sont un citoyen de première classe du populaire « GitFlow », et de nombreuses organisations ont créé des modèles de branchement personnalisés qui s’appuient fortement sur les branches de fonctionnalités. Les branches de fonctionnalité permettent aux développeurs individuels de travailler de manière isolée jusqu’à ce que leur fonctionnalité soit terminée, afin qu’ils n’aient pas à être négativement impactés par les modifications de quelqu’un d’autre. Certaines organisations vont jusqu’à utiliser des branches de longue durée pour isoler des équipes entières lorsque plusieurs équipes travaillent dans la même base de code. D’autres les utilisent pour isoler plusieurs versions qui sont construites simultanément.
Finalement, toutes ces choses construites de manière isolée doivent être fusionnées pour les amener à la production, et c’est là que le risque apparaît. Lorsque deux branches sont fusionnées et que chacune comporte de grandes quantités de modifications, il est presque impossible de savoir avec certitude qu’entre Git et notre résolution manuelle des conflits, chaque situation a été gérée correctement. Encore une fois, Git ne sait rien du contexte, du but ou de la sémantique. Il ne pense qu’à l’ordre.
Les développeurs apprennent que les branches de fonctionnalité de longue durée conviennent tant que vous fusionnez périodiquement de nouvelles modifications dans la branche cible (la destination de la fusion à venir) dans votre branche de fonctionnalité. Ceci est censé vous maintenir en ligne avec tout le monde. Malheureusement, c’est un miracle. Si 5 développeurs d’une équipe ont tous travaillé sur des branches de fonctionnalités distinctes pendant un certain temps, peu importe la fréquence à laquelle ils fusionnent la branche cible dans leurs branches respectives. Ils ne sont toujours pas intégrés. Une quantité importante de changements s’est produite qui n’est visible pour personne car les gens ne sont pas encore prêts à fusionner.
Et si ce n’était pas 5 développeurs mais 25 ou 75, travaillant tous dans la même base de code ? Ces fusions sont effectuées vers la fin du sprint, et il est très long de vérifier que tout a été correctement géré. Une intégration retardée crée toujours un risque inutile et le place souvent au moment où vous le souhaitez le moins, lorsque vous terminez un sprint ou une version.
Développement basé sur le tronc
Considérons maintenant le développement basé sur le tronc, qui demande aux développeurs de pousser de petits commits bien testés quotidiennement, voire plusieurs fois par jour, dans une branche de tronc commune généralement appelée « maître ». Les branches de maintenance sont créées au fur et à mesure que les versions sortent, mais tout nouveau développement va directement dans la branche principale.
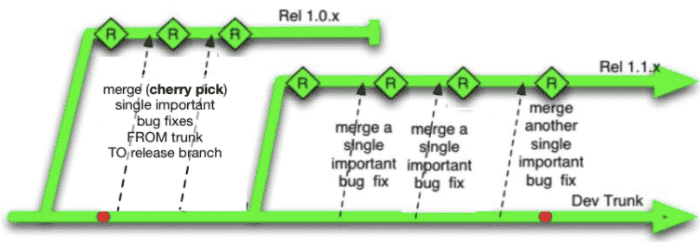
Développement basé sur le tronc.
Les grandes fonctionnalités sont décomposées en petits morceaux, et les développeurs utilisent le basculement des fonctionnalités pour masquer leurs modifications jusqu’au moment de la mise en ligne. Il s’agit d’une véritable intégration continue, qui a plusieurs implications importantes pour nous :
- Il n’y a pas de branches de fonctionnalités, donc chaque développeur construit le code d’aujourd’hui sur le code d’hier de tout le monde.
- Pas de fusion de branches – il suffit de valider et de pousser les modifications vers les branches de tronc et de maintenance.
- Les bogues destinés à une branche de maintenance sont toujours d’abord corrigés dans le tronc, puis sélectionnés dans la branche de maintenance (pour éviter les problèmes de régression).
Avantages
- La possibilité de conflits de fusion a été considérablement réduite. Moins de code a changé, donc nous avons peu de possibilités de conflit.
- Les engagements fréquents dans le tronc obligent les développeurs à prendre en compte la qualité tout au long du cycle de construction plutôt que de la conserver jusqu’à la fin (petit changement, test, push ; petit changement, test, push).
- Les conflits sont détectés tôt lors de la construction, plutôt que tardivement au moment de la fusion.
- L’intégration continue crée une véritable fenêtre sur l’état actuel du code, la version, etc. Rien ne se cache dans l’ombre.
Une intégration retardée peut également vous obliger à stabiliser plusieurs fois le même code. Par exemple, certaines équipes testent et stabilisent les fonctionnalités dans la branche de fonctionnalités afin qu’elles puissent être testées de manière isolée. Une fois la fusion effectuée, il est très possible que la fonctionnalité se soit déstabilisée et que vous deviez maintenant recommencer ce processus. Ou vous pourriez supposer qu’il est stable puisqu’il fonctionnait dans la branche de fonctionnalité et le laisser simplement sortir de cette façon. Tout cela pourrait être évité si nous nous intégrions tôt.
Le problème n’est pas Git ; C’est comment nous l’utilisons
Git a de nombreuses fonctionnalités fantastiques. Sa capacité de fusion est bien au-dessus de ce qui est fourni par les concurrents de Git. Ceux d’entre nous qui l’ont utilisé ont tous vu les changements de fusion de Git avec succès sans notre aide, ce qui peut nous endormir dans un faux sentiment de sécurité. Le problème n’est pas du tout Git. C’est comme ça qu’on s’en sert. La chose la plus sage que nous puissions faire est de faire des efforts pour comprendre ce qu’est l’outil et ce qu’il n’est pas. Une fois que nous avons fait cela, nous pouvons l’utiliser comme prévu et arrêter de nous blesser avec.
Cet article est exact et fidèle au meilleur de la connaissance de l’auteur. Le contenu est uniquement à des fins d’information ou de divertissement et ne remplace pas un conseil personnel ou un conseil professionnel en matière commerciale, financière, juridique ou technique.