Tesfaye écrit sur les architectures d’apprentissage en profondeur et d’autres concepts de programmation informatique.
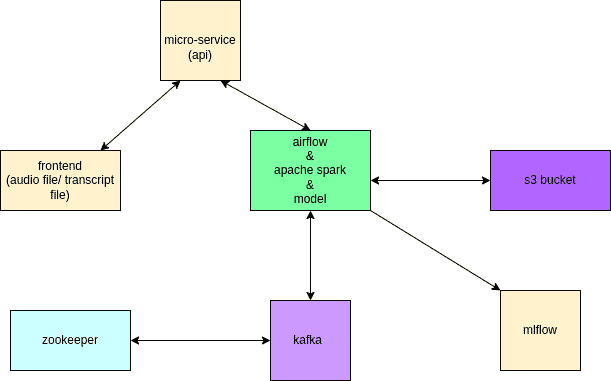
Schéma simple de l’approche
Introduction
Le manque et la qualité des données sont deux des éléments les plus importants à prendre en compte lors de la construction d’un modèle. Dans cet article, nous discuterons d’un projet qui permet à un modèle de synthèse vocale amharique de mieux s’entraîner à mesure qu’il acquiert plus de données. Nous allons produire un outil pour traiter la publication et la réception de fichiers texte et audio depuis et vers un lac de données (seau S3), appliquer la transformation de manière distribuée et le charger dans un entrepôt dans un format approprié pour former un discours à modèle de texte.
Objectif du projet
10 Academy est le client. Reconnaissant la valeur des grands ensembles de données pour les ensembles de données parole-texte, voyant l’opportunité qu’il existe de nombreux corpus de texte pour la langue amharique, ce projet tente de construire un pipeline d’ingénierie de données qui permet d’enregistrer des millions de locuteurs amhariques lisant des textes numériques sur plateformes web.
Il existe un certain nombre de grands corpus de texte que nous utiliserons, mais dans le but de tester le développement du backend, nous utiliserons les données fournies dans cet ensemble de données.
Les plateformes et outils suivants ont été utilisés pour le projet :
Apache Kafka
Une plate-forme de messagerie populaire basée sur le mécanisme pub-sub. Il s’agit d’un système distribué, tolérant aux pannes et à haute disponibilité. La majorité des entreprises utilisent Kafka à des fins diverses, mais son architecture orientée services, qui est indépendante des langages de programmation et étend sa convivialité, est sa caractéristique la plus forte. L’intégration avec Python est l’un des cas d’utilisation de Kafka (Important dans notre cas). Les programmes basés sur Python actuellement en cours d’exécution peuvent communiquer entre eux à l’aide de la file d’attente de messages Kafka.
Flux d’air Apache
Un gestionnaire de flux de travail pour planifier, orchestrer et surveiller les flux de travail. Selon sa définition, il s’agit d’une « plate-forme d’Airbnb pour créer, programmer et surveiller par programmation des pipelines de données ». Il rationalise les procédures d’entreprise de plus en plus complexes et repose sur l’idée de « Configuration en tant que code ». Les graphiques acycliques dirigés (DAG) sont utilisés par Airflow pour contrôler l’orchestration du flux de travail. Il permet aux ingénieurs de données de mettre en place et de contrôler des flux de travail composés de nombreuses sources de données.
Apache Étincelle
Un moteur d’analyse pour les données non structurées et semi-structurées qui a un large éventail de cas d’utilisation. Il prend en charge un large éventail d’applications, y compris le traitement de flux et l’apprentissage automatique, grâce à son style de programmation simple et expressif.
Données
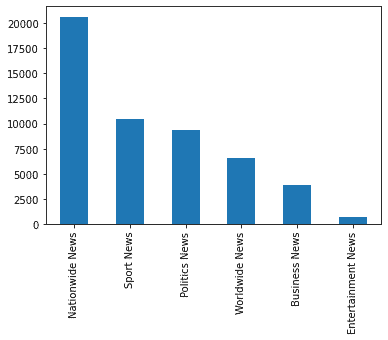
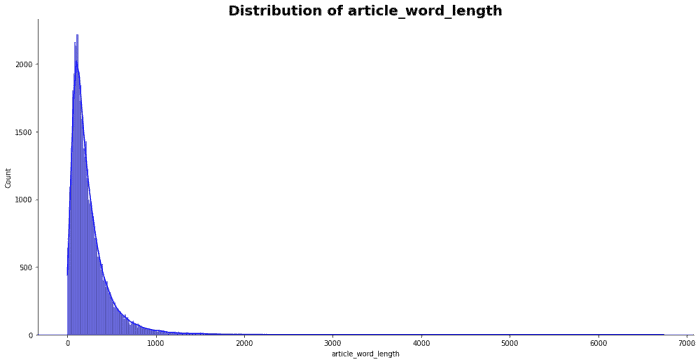
Pour ce projet, nous avons une classification contenant des textes d’actualité en amharique avec des performances de base. Les données contiennent des articles contenant un grand nombre de mots. Nous avons donc effectué un prétraitement simple pour diviser ces articles en phrases et nous assurer que l’espacement entre les mots est correct. Voici quelques aperçus des données :
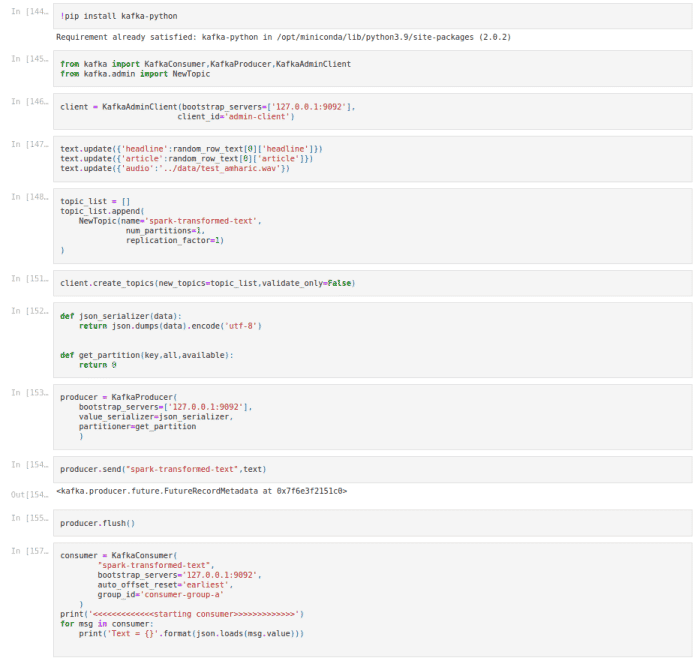
Approche et configuration
Comme nous pouvons le voir, nous avons quelques composants principaux sur le diagramme. Cela inclut
- L’extrémité avant – créé avec Reactjs, est la façon dont nous interagissons avec les utilisateurs pour télécharger un fichier audio ou valider les soumissions de fichiers audio.
- Back-end (API microservice) – Django sera utilisé pour construire le backend (API microservice), ce qui facilitera la communication entre le frontend et Kafka pour une connexion transparente.
- Flux d’air – Le devoir d’Airflow est d’orchestrer les messages de Kafka tout en commençant la transformation et le chargement des données sur Spark.
- Étincelle – Spark sera utilisé pour convertir et charger les données au fur et à mesure que nous les normalisons pour assurer la cohérence et la fiabilité.
- Amas de Kafka – Ce sera le cerveau de l’ensemble du système car il facilite la production de messages (ex. fichiers audio) sur un sujet pour le publier aux consommateurs.
Mise en oeuvre du projet
La mise en œuvre du projet peut être expliquée par étapes.
Faites défiler pour continuer
1. Génération de texte aléatoire à partir de l’ensemble de données prétraité – Tout d’abord, nous devons connecter la session spark à un cluster Kafka. Nous avons utilisé Pyspark pour générer le texte aléatoire à partir de l’ensemble de données prétraité.
2. Diffuser les données – Ici, nous utilisons le cluster Kafka, pour diffuser les données générées dans le frontend pour que l’utilisateur puisse les voir. nous enverrons et publierons les données textuelles aléatoires, en gardant à l’esprit que nous avions généré l’UUID de manière unique et que nous le configurons avec l’API Django, donc il n’y aura pas de chevauchement avec les données, donc une fois que nous les aurons reçues.
3. Enregistrer ou télécharger de l’audio – Ici, nous verrons le texte généré sur le front-end et l’utilisateur lira le texte, s’enregistrera, puis téléchargera le fichier audio vers le back-end. A ce stade, nous allons placer le fichier à l’intérieur du bucket S3, et l’Airflow lance le prétraitement et la validation des données
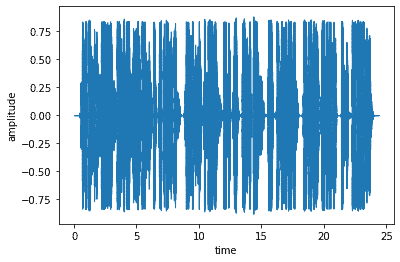
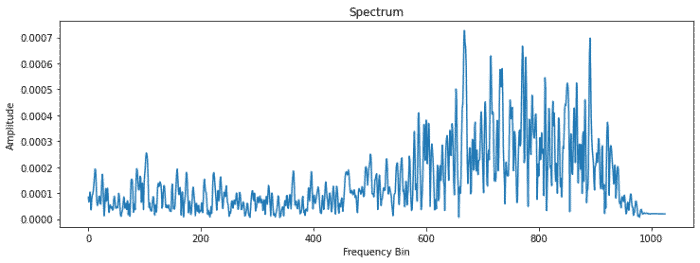
4. Prétraitement de l’audio d’entrée – Donc, une fois que nous avons reçu le fichier audio, nous commençons à l’examiner attentivement, à le nettoyer et à le faire passer. certains chèques comprennent
- nous vérifions d’abord si le fichier audio contient des données en affichant une simple forme d’onde
- nous vérifions les fréquences du fichier audio pour voir si elles sont normales
- nous le convertissons en un spectrogramme et vérifions les mfccs, pour voir si les 12 coefficients standard, s’ils ont un certain modèle.
5. Validation de l’audio d’entrée – La validation à ce stade peut se faire de plusieurs façons, mais pour ce projet, nous allons le garder simple et vérifier les silences et compter les mots. nous le faisons en divisant le fichier audio en morceaux, c’est-à-dire des mots, puis nous le stockons et comptons le nombre de morceaux s’ils sont similaires à la longueur de la chaîne d’articles divisée.
6. Transformation et stockage dans un compartiment s3 – Ici, nous utilisons les données audio prétraitées, si elles réussissent la validation, nous stockerons le fichier audio en faisant correspondre l’identifiant du texte et mettrons à jour nos métadonnées. Tout ici a été fait à l’aide d’étincelles.

sept. Planification du recyclage du modèle – À ce stade, nous avons les audios de qualité collectés et validés disponibles avec leurs métadonnées. Donc, ce dont nous avons besoin maintenant pour terminer le projet, c’est de recycler le modèle en utilisant les nouveaux fichiers audio. Cela sera programmé à l’aide d’Airflow.

Leçons apprises
Dans ce projet, j’ai appris à utiliser Kafka, Airflow et Spark ensemble pour obtenir un meilleur résultat. Même si Spark n’était pas nécessaire pour notre projet, cela a été un excellent ajout de savoir comment il se connecte avec d’autres outils car à mesure que les données grossissent, l’utilisation d’outils comme Spark deviendra nécessaire. J’ai appris comment interagir avec chaque péage en utilisant Python et comment cela faciliterait les choses à l’avenir à mesure que nos données augmenteraient.
Travaux futurs
En raison de contraintes de temps, nous n’avons pas pu terminer tout ce que nous voulions faire sur ce projet. Donc, à l’avenir, nous voulons inclure
– Ajoutez un sujet de validation et utilisez-le pour valider le fichier audio généré avec un autre utilisateur
– Réentraînement complet d’un modèle de synthèse vocale pour voir l’amélioration avec le calendrier Airflow (a été mis en œuvre mais des améliorations sont nécessaires)
Ce contenu est exact et fidèle au meilleur de la connaissance de l’auteur et ne vise pas à remplacer les conseils formels et individualisés d’un professionnel qualifié.