Tesfaye écrit sur des projets impliquant une architecture d’apprentissage en profondeur et des technologies décentralisées comme la blockchain et les NFT.
Objectif du projet
Judea Pearl et son équipe de recherche ont construit une base théorique solide pour l’inférence causale au cours des dernières décennies, mais le processus d’intégration avec l’apprentissage automatique conventionnel ne fait que commencer. Nous avons des données de diagnostic du cancer du sein de Kaggle pour ce projet (à l’origine de l’UCI Machine Learning Repository).
Notre objectif est de combiner l’apprentissage automatique avec le cadre de Pearl pour exécuter une tâche d’inférence causale.
- Causalnex—Bibliothèque Python qui utilise les réseaux bayésiens pour combiner l’apprentissage automatique et l’expertise du domaine pour le raisonnement causal. Vous pouvez utiliser CausalNex pour découvrir des relations structurelles dans vos données, apprendre des distributions complexes et observer l’effet d’interventions potentielles.
- MLflow—Cadre qui joue un rôle essentiel dans tout cycle de vie d’apprentissage automatique de bout en bout. Il permet de suivre vos expériences ML, y compris le suivi de vos modèles, paramètres de modèle, ensembles de données et hyperparamètres et de les reproduire si nécessaire.
- Contrôle de la version des données (DVC)—Outil de gestion des données et des expériences ML qui tire parti de l’ensemble d’outils d’ingénierie existant que nous connaissons (Git, CI/CD, etc.).
Données utilisées
Pour ce projet, nous allons utiliser les données de diagnostic du cancer du sein de Kaggle (à l’origine de l’UCI Machine Learning Repository). Il contient 33 colonnes (caractéristiques) et 569 lignes (données). Les caractéristiques sont calculées à partir d’une image numérisée d’une aspiration à l’aiguille fine (FNA) d’une masse mammaire. Ils décrivent les caractéristiques des noyaux cellulaires présents dans l’image. La variable cible est appelée « diagnostic » et contient la valeur M pour malin ou B pour bénin.
Informations dérivées des données
La distribution des caractéristiques peut être vue à l’aide du graphique violet ; La classification des caractéristiques peut être vue à l’aide du diagramme en essaim et les diagrammes en boîte aideront à comparer la médiane et à détecter les valeurs aberrantes (tous les diagrammes montrent les 10 premières caractéristiques pour une meilleure visualisation).

Implémentation et visualisation du graphe causal
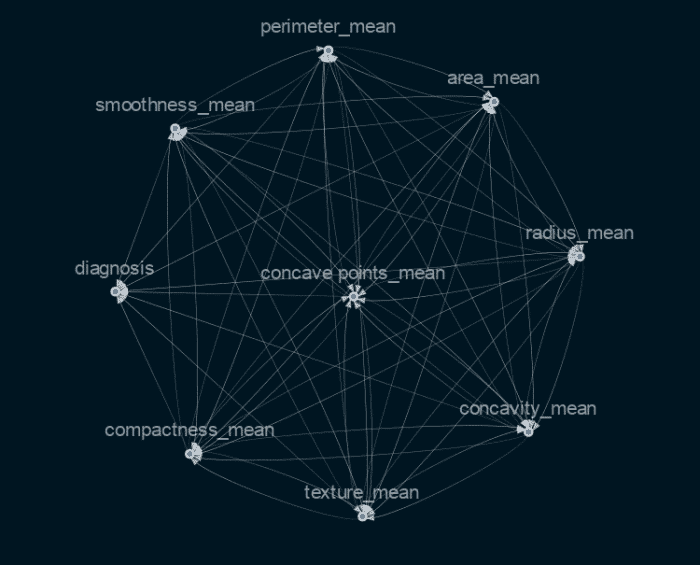
La sélection des variables qui sont cruciales pour déterminer une cause et un effet dans cette situation nécessite des connaissances ou des compétences dans le domaine de la médecine (pour notre projet). Bien qu’il existe des techniques plus techniques pour sélectionner les fonctionnalités les plus cruciales, j’ai choisi pour mon projet d’utiliser des métriques de fonctionnalités importantes découvertes à l’aide du classificateur XgBoost. En conséquence, j’ai obtenu ce graphique causal.
Comme vous pouvez le voir, le graphique est très interconnecté et ne montre pas clairement quelles caractéristiques influencent directement le résultat et lesquelles ne le font pas. Nous utiliserons donc la fonctionnalité Causalnex dans ce cas, qui seuille les bords les plus faibles.
Stabilité du graphique
La stabilité du graphe causal sera ensuite testée à l’étape suivante. J’ai donc fait plusieurs itérations du graphique causal ci-dessus pour cette tâche en utilisant des sous-ensembles des données d’origine. Ensuite, j’ai comparé les graphiques à l’aide de l’indice de similarité Jaccard, qui calcule l’intersection et l’union des arêtes du graphique.
Les résultats comprennent :
- La similarité entre les données à 80 % et le graphique causal à 100 % des données – 92,6 %
- La similarité entre 50 % de données et 80 % de données causales – 81,43 %
- La similarité entre 80 % de données et 90 % de données causales – 100 %

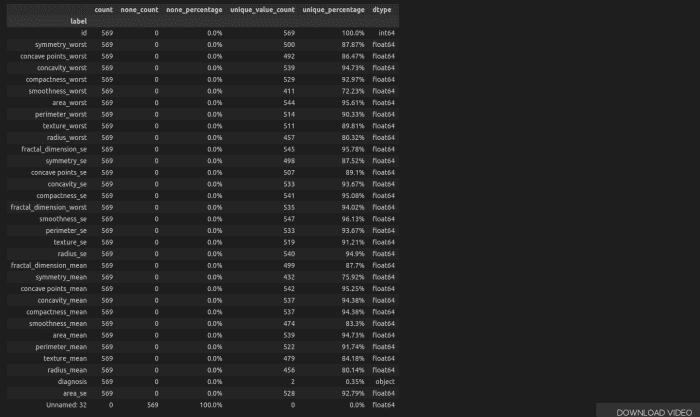
Discrétisation des Dataframe Features
Ici, nous allons changer la trame de données avec des données continues en discrète. Nous pouvons voir ci-dessous que les valeurs sont trop uniques, ce qui peut montrer que le dataframe est davantage constitué de données continues.
Avant de discrétiser le dataframe
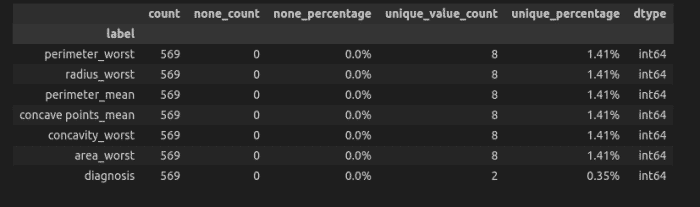
Après discrétisation du dataframe
Ajustement de la distribution conditionnelle du réseau bayésien
Il a été complété à l’aide d’une version discrète des données originales et du modèle de structure. Afin de convertir mes données d’origine en données discrètes, j’ai utilisé la « DecisionTreeSupervisedDiscretiserMethod » de causalnex. J’ai pu prédire et obtenir des scores pour la prédiction après avoir ajusté le réseau bayésien.
- Le score de précision était de 88 %
- Le score de précision était de 100 %

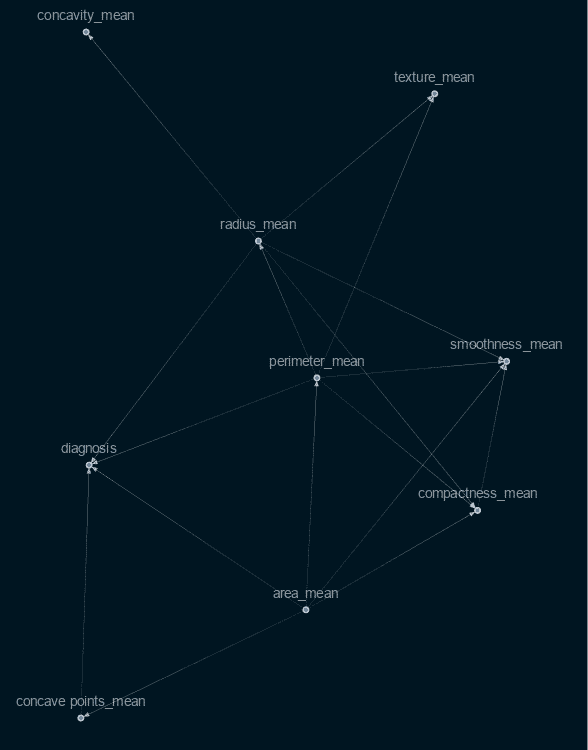
Ajustement avec uniquement des graphiques directement connectés
Suite à l’entraînement de ce modèle avec toutes les variables, j’ai choisi d’entraîner un modèle différent avec uniquement les facteurs directement liés à la variable cible (diagnostic), et j’ai obtenu les résultats suivants :
- Le score de précision était de 91 %
- Le score de précision était de 100 %

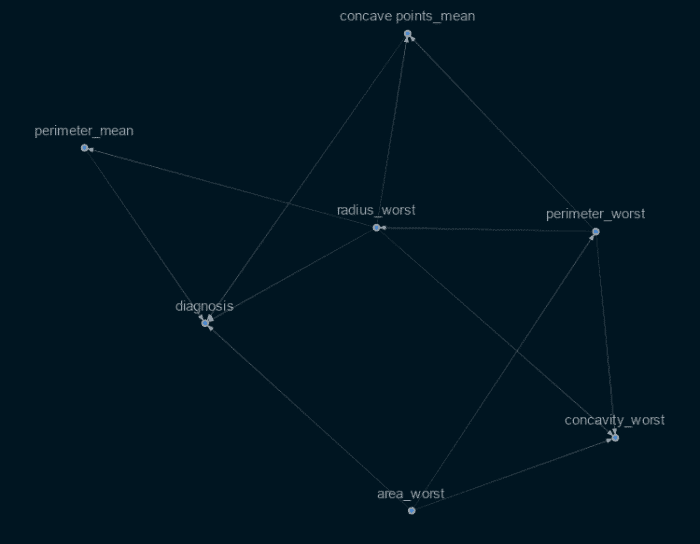
Graphe causal avec uniquement des nœuds directs
Cela démontre que les principales caractéristiques du graphique peuvent vraiment fournir une meilleure prédiction que d’autres caractéristiques précédemment sélectionnées. Cependant, bien que produisant de bons résultats, le modèle n’a pas pu correspondre aux prédictions faites à l’aide des modèles XgBoost et de classificateur de forêt aléatoire.
- Score de précision XgBoost – 97% et score de précision – 97%
- Forêt aléatoire Score de précision – 98 % et score de précision – 99 %
Conclusion et travaux futurs
Dans ce projet, nous avons examiné l’utilisation de l’apprentissage automatique et de l’inférence causale. Nous avons examiné les données, visualisé le graphique causal, joué avec et vérifié s’il était stable.
Nous avons également pu faire des prédictions à l’aide du modèle, ce qui est un bon résultat car faire une inférence causale consiste davantage à déterminer ce qui a causé un événement qu’à faire des prédictions. Et nous avons vu que nous pouvons obtenir de meilleurs résultats simplement en utilisant les qualités qui ont été déterminées par inférence causale, ce qui est encourageant pour améliorer la mise en œuvre et obtenir de meilleurs résultats.
Les travaux futurs impliqueront la réalisation de diverses statistiques, telles que le Do-calcul, et la recherche de l’importance des caractéristiques à l’aide de méthodes permettant d’obtenir le graphique le plus correct.