Ron est un ingénieur à la retraite et directeur d’IBM et d’autres entreprises de haute technologie. Il s’est spécialisé dans la conception matérielle et logicielle.

Domaine PublicImages de Pixabay
En tant qu’écrivain qui publie des articles sur divers sites sur Internet, je voulais créer une archive en ligne pour mon travail. Ce serait un référentiel auquel je pourrais donner accès à d’autres au besoin. Un exemple serait d’établir la paternité dans les affaires de violation du droit d’auteur (DMCA). En même temps, pour éviter que des fichiers en double avec le même contenu n’apparaissent dans les résultats de recherche, j’avais besoin d’empêcher les fichiers de mes archives d’être indexés par des moteurs de recherche tels que Google ou Bing.
Une petite recherche a montré qu’en utilisant un robots.txt fichier, je pourrais informer les moteurs de recherche qu’ils ne doivent pas indexer certains éléments sur mon site Web. C’est une solution simple et facile qui fait exactement ce dont j’ai besoin. Mais lors de la configuration de mon fichier robots.txt, j’ai rencontré des problèmes qui n’étaient pas résolus dans la documentation que j’avais lue, et qui nécessitaient du temps et des casse-tête pour être résolus par essais et erreurs.
C’est pourquoi j’ai pensé qu’il pourrait être utile de fournir un guide simple qui pourrait éviter à quelqu’un d’autre d’avoir à se débattre avec les problèmes que j’ai rencontrés.
Qu’est-ce que robots.txt ?
Les moteurs de recherche utilisent des applications appelées « robots » pour « explorer » l’ensemble d’Internet, rechercher des fichiers en ligne et les ajouter à une base de données. Lorsqu’un utilisateur saisit un terme de recherche dans Google, par exemple, cette requête est comparée à la base de données de sites Web de Google qu’elle a explorée. C’est à partir de cette base de données interne qu’une liste de résultats de recherche est produite pour l’utilisateur.
Le fichier robot.txt est utilisé pour mettre en place un panneau KEEP OUT pour les fichiers de votre site Web que vous ne voulez pas que les robots des moteurs de recherche voient. Étant donné que ces fichiers seront ignorés par le robot, ils ne seront pas indexés dans la base de données du moteur de recherche et ils n’apparaîtront pas dans les résultats de recherche.
Les moteurs de recherche réputés programment tous leurs robots pour rechercher le fichier robot.txt sur chaque site Web qu’ils trouvent. Si ce fichier existe, le robot suivra ses instructions concernant tous les fichiers ou dossiers que le robot doit ignorer.
(Notez que tout cela est entièrement volontaire de la part du moteur de recherche. Les moteurs de recherche malveillants peuvent ignorer et ignorent les instructions dans robot.txt. En fait, certains méchants peuvent en fait être attirés par les parties de votre site Web que robot.txt indique à éviter sur la théorie que si vous voulez le cacher, il pourrait y avoir quelque chose qu’ils peuvent exploiter).
Comment configurer un fichier robots.txt
Je vais décrire comment j’ai configuré mon fichier robots.txt pour répondre à mon besoin spécifique. Vous pouvez lire une description plus générale des différentes façons d’utiliser robots.txt ici. Notez que pour utiliser cette méthode, vous devez avoir votre propre site Web avec son propre nom de domaine.
L’utilisation de robots.txt pour restreindre l’accès à vos fichiers ne fonctionne que si vous avez votre propre site Web avec son propre nom de domaine. En effet, le fichier robots.txt ne peut résider que dans le répertoire de niveau supérieur de votre site Web et vous ne pourrez apporter des modifications à ce répertoire que si vous êtes propriétaire du site.
Par exemple, si votre site Web est
http://www.myownwebsite.com
alors le fichier robots.txt doit avoir le nom
http://www.myownwebsite.com/robots.txt
Si vous placez votre fichier robots.txt ailleurs sur le site, il ne sera pas reconnu. Par exemple, si vous placez votre robots.txt dans un dossier appelé mygoodstuff,
Faites défiler pour continuer
http://www.myownwebsite.com/mygoodstuff/robots.txt
ou dans un sous-domaine tel que
http://www.mygoodstuff/myownwebsite.com/robots.txt
les robots d’exploration Web ne le reconnaîtront pas et ne respecteront pas ses instructions.
En raison de cette restriction, vous ne pouvez pas le faire avec un site WordPress gratuit tel que https://myfreewebsite.wordpress.com. Vous pouvez voir le fichier robots.txt sur wordpress.com (https://wordpress.com/robots.txt) mais vous ne pouvez pas le modifier.
Si vous souhaitez afficher le fichier wordpress.com robots.txt, entrez simplement https://wordpress.com/robots.txt dans le champ URL de votre navigateur et appuyez sur Entrée. Vous pourrez voir le contenu du fichier, mais vous ne pourrez pas le modifier.
Notez également que les majuscules comptent ! Le nom du fichier doit être robots.txt et rien d’autre. ROBOTS.TXT ou Robots.Txt ne fonctionneront pas.
Le contenu d’un fichier robots.txt
Voici à quoi pourrait ressembler le contenu d’un fichier robots.txt typique :
Agent utilisateur: *
Interdire : /dossier-à-ignorer/
la agent utilisateur terme spécifie les moteurs de recherche particuliers auxquels cette directive s’adresse. Le * dans l’exemple ci-dessus signifie qu’il s’applique à tous les moteurs de recherche. Si vous souhaitez que vos instructions ne s’appliquent qu’à Google, par exemple, vous utiliserez :
Agent utilisateur : Google
Interdire : /dossier-à-ignorer/
Cela empêcherait uniquement Google, et aucun autre moteur de recherche, d’accéder aux dossiers ou fichiers que vous répertoriez.
la Refuser terme spécifie quels dossiers ou fichiers ne doivent pas être recherchés ou reconnus par le robot. Dans l’exemple ci-dessus, je ne veux pas le contenu d’un dossier appelé dossier à ignorer être indexé par les moteurs de recherche. Ainsi, mon instruction Disallow indique aux robots d’exploration Web d’ignorer l’URL suivante :
http://www.myownwebsite.com/folder-to-ignore/
Plusieurs dossiers ou fichiers peuvent être spécifiés :
Agent utilisateur: *
Interdire : /dossier-à-ignorer/
Interdire : /un autre dossier/
Interdire : /troisième dossier/sous-dossier/
Interdire : /un-dossier/monfichier.html
Création d’un fichier robots.txt
N’importe quel éditeur de texte, tel que le Bloc-notes sous Windows, peut être utilisé pour créer des fichiers robot.txt. Notez que si un éditeur de document, tel que Microsoft Word, est utilisé, la sortie doit être enregistrée en tant que fichier .txt. Sinon, le fichier peut contenir des codes cachés qui invalideront son contenu.
Une fois enregistré en tant que texte, le fichier doit être téléchargé dans le répertoire de niveau supérieur de votre site Web. Sur la plupart des serveurs, ce sera le dossier public_html.
Téléchargez robots.txt exactement de la même manière que vous téléchargez normalement des fichiers sur le site. Dans la plupart des cas, cela impliquera l’utilisation d’une application FTP telle que le client gratuit et open source FileZilla. Assurez-vous que le fichier est placé dans le bon dossier.
VIDÉO : Comment créer un fichier robots.txt
Test de votre fichier robots.txt
Il est très important de tester la configuration de votre robots.txt pour vous assurer qu’il fonctionne comme vous le souhaitez. Sinon, vous constaterez peut-être que les dossiers que vous vouliez bloquer sont toujours accessibles aux robots d’exploration et s’affichent dans les résultats de recherche. Une fois que cela se produit, cela peut prendre des semaines, voire des mois, pour les faire supprimer de la base de données du moteur de recherche.
Plusieurs testeurs gratuits de robots.txt sont disponibles sur le Web. Voici ceux que j’ai utilisés :
Testeur robots.txt de Google Webmaster Tools (nécessite un compte Google)
http://www.searchenginepromotionhelp.com/m/robots-text-tester/robots-checker.php
Les GOTCHA qui m’ont eu !
Google n’a pas pu voir mon fichier robots.txt
J’ai configuré mon fichier robots.txt pour bloquer un dossier appelé /Archives YCN/. J’ai créé ce dossier sur mon site Web et vérifié qu’il était accessible comme prévu.
J’ai ensuite créé un fichier robots.txt avec le contenu suivant :
Agent utilisateur: *
Interdire : /Archive YCN/
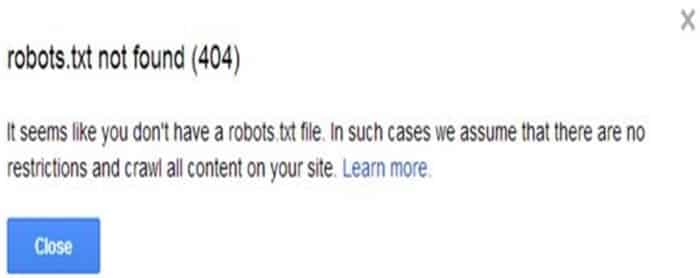
Après avoir téléchargé ce fichier dans mon répertoire de niveau supérieur, je l’ai testé à l’aide du testeur robots.txt dans les outils pour les webmasters de Google. Bien que j’aie suivi attentivement les instructions données via le lien Outils pour les webmasters ci-dessus, j’ai immédiatement rencontré un problème. Voici le message d’erreur totalement inattendu que j’ai reçu :
Ron Franklin
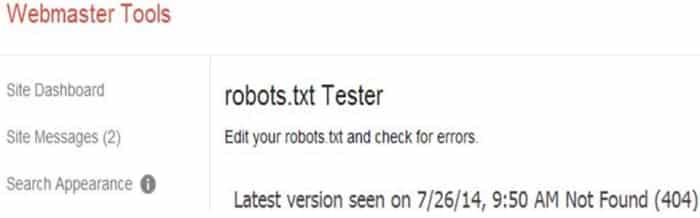
Mais le robot.txt était là ! Je pouvais le voir dans la liste des fichiers de mon site Web, exactement là où il était censé se trouver. Pourquoi Google ne pouvait-il pas le voir ? Finalement, j’ai vu quelque chose sur la page du testeur que je n’avais pas remarqué auparavant.
Ron Franklin
La clé était dans la ligne qui dit : « Dernière version vue le 26/07/14… » (je faisais le test plusieurs jours après le 26/07). Lorsque j’ai lancé le test, il semble que Google n’ait pas examiné l’état du site Web à ce moment-là, mais s’est apparemment appuyé sur son image interne de ce à quoi ressemblait le site Web la dernière fois qu’il l’a exploré.
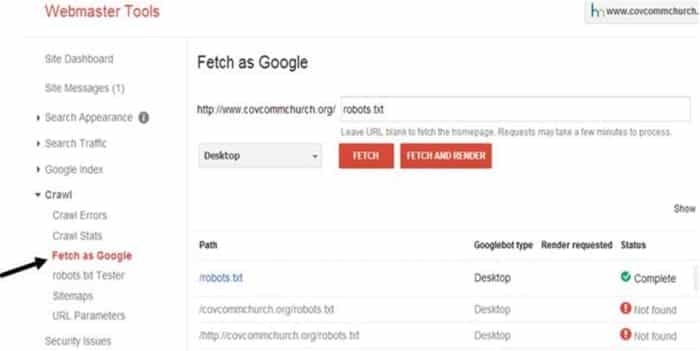
J’avais besoin que Google ait une image actuelle de ce qui se trouvait sur mon site Web. J’ai provoqué cela en utilisant la fonction Fetch as Google.
Ron Franklin
Une fois la fonction Fetch as Google exécutée, Google a pu trouver le fichier robots.txt.
Voici un autre point auquel il faut faire attention. Dans le testeur robots.txt, Google a répertorié mon site Web de deux manières différentes :
myownwebsite.org
http://myownwebsite.org
Bien sûr, ces deux entrées se réfèrent exactement à la même URL. Mais j’ai dû faire des récupérations Google individuelles pour que le fichier robots.txt soit reconnu. J’ai également effectué des tests séparés sur chacun afin de m’assurer que mes instructions de blocage seraient exécutées, quelle que soit l’URL utilisée pour accéder au site.
Mon fichier robots.txt n’a pas fonctionné !
Maintenant que Google pouvait voir mon fichier robots.txt, j’ai lancé le test, confiant de réussir. Cela ne fonctionnait toujours pas. Cette fois, le test a signalé que bien que mon fichier robots.txt soit désormais reconnu, il ne bloquait pas l’accès au dossier /YCN Archive/. L’accès du robot d’exploration Web à ce dossier était toujours « AUTORISÉ ».

Aucun espace autorisé dans le nom du dossier ou du fichier interdit
Je savais que mon fichier robots.txt était configuré correctement, donc cela m’a déconcerté pourquoi il ne bloquait pas l’accès au dossier spécifié. Il m’a fallu du temps pour comprendre ce qui se passait. Mon dossier avait un espace dans le nom ! Lorsque j’ai renommé le dossier pour supprimer l’espace, le testeur Google robots.txt a montré que le dossier était bloqué.
Ron Franklin
robots.txt fait son travail
Depuis que j’ai mis en place mon robot.txt, il fait son travail silencieusement et efficacement. Mes fichiers sont archivés en ligne en toute sécurité et peuvent être consultés par toute personne à qui je donne l’URL. Mais aucun d’entre eux n’apparaît dans les résultats des moteurs de recherche.
Cet article est exact et fidèle au meilleur de la connaissance de l’auteur. Le contenu est uniquement à des fins d’information ou de divertissement et ne remplace pas un conseil personnel ou un conseil professionnel en matière commerciale, financière, juridique ou technique.
© 2014 Ronald E Franklin
Ronald E. Franklin (auteur) de Mechanicsburg, Pennsylvanie, le 16 septembre 2014 :
Salut, kislanik. C’est intéressant avec WordPress. J’ai regardé mon WordPress robots.txt, mais je n’ai pas réalisé que c’était virtuel. Pour moi c’est bien; Je ne voulais pas le changer de toute façon. Merci pour la lecture et le partage.
Marika de Chypre le 15 septembre 2014 :
J’ai utilisé cette astuce tout le temps et sur certains de mes sites, je la peaufine au fur et à mesure (dans mon cPanel). bon conseil !
Au fait, quelque chose que j’ai remarqué récemment – si vous avez un blog WordPress, le fichier robots.txt est virtuel, ce qui signifie qu’il n’existe pas réellement. Trop de temps pour comprendre une fois quand j’avais besoin de changer… un peu nul, mais bon…
Ronald E. Franklin (auteur) de Mechanicsburg, Pennsylvanie le 05 août 2014 :
Merci, Mel. En fait, cela a été provoqué par la fermeture de Yahoo Voices, ainsi que par la nécessité d’avoir une preuve de la paternité de plusieurs de mes articles Yahoo qui avaient été piratés. Ainsi, un écrivain peut soudainement avoir besoin de ce type d’informations à tout moment.
Mel Carrière de Snowbound and down dans le nord du Colorado le 05 août 2014 :
Je ne pense pas voir la nécessité de le faire à ce stade. Je suis occupé à ce carrefour à essayer d’amener les moteurs de recherche à me trouver davantage. Néanmoins, c’est une excellente information à stocker pour une utilisation future et elle a été présentée avec beaucoup de compétence !
Ronald E. Franklin (auteur) de Mechanicsburg, Pennsylvanie le 05 août 2014 :
Merci Rachel. Fait intéressant, lors de la configuration du robots.txt de mon site Web, j’ai également regardé dans Google Webmaster Tools le robots.txt de mon sous-domaine HubPages. C’est là, même si bien sûr nous n’avons pas accès pour le changer.
Rachael O’Halloran des États-Unis le 05 août 2014 :
C’est une excellente information. Je ne peux pas l’utiliser ici sur HubPages, mais je peux l’utiliser sur mes blogs. Merci!